Inference-Time Scaling with Verifiers: Democratizing AI Reasoning
As generative models become increasingly powerful, a fundamental question re-emerges: how can we effectively leverage these models for reasoning tasks? While large-scale models have demonstrated remarkable capabilities in generation, adapting them to specific reasoning problems remains a significant challenge. This article explores one promising direction: inference-time scaling with verifiers, which represents not just a technical improvement, but a potential paradigm shift in how AI systems adapt to diverse real-world problems.
Bridging Generation and Reasoning

Understanding Reasoning Tasks from a Generative Perspective
From the perspective of generative models, reasoning tasks present a unique challenge. While general generation tasks involve sampling from relatively broad probability distributions, reasoning tasks require finding solutions within extremely sparse, highly selective distributions.
Consider a simple example: when generating text continuations for “Today’s weather is…”, a model can validly produce numerous outputs—sunny, cloudy, rainy, etc. However, for a reasoning task like “2, 4, 8, 16, ?”, only one answer is correct: 32. This represents a fundamental shift from distributed probability mass to extremely concentrated solutions.
In this light, we can understand the challenge of applying generative models to reasoning as an adaptation problem: how do we guide a model trained on general distributions to navigate toward the sparse regions required by specific reasoning tasks?
Existing Approaches Reconsidered
Many existing methods for improving reasoning ability in large generative models can be reconsidered through this lens:
Chain of Thought (CoT) 1 attempts to more precisely match the sparse distribution of reasoning tasks by adding intermediate token generation steps, essentially providing stepping stones toward the correct answer.
Reinforcement Learning with Verifiable Rewards (RLVR) 2 fine-tunes models to adapt to sparse reasoning distributions using pre-collected datasets and reward signals.
Inference-time scaling with verifiers 3 4 offers a different approach: rather than modifying the model itself, it uses task-specific verifiers to guide the generation process toward valid solutions during inference.
What Are Verifiers?
Verifiers are external functions or models that evaluate whether a generated solution meets the requirements of a specific reasoning task. Unlike the base generative model, verifiers are designed to be:
- Task-specific rather than general-purpose
- Focused on correctness rather than fluency
- Implementable by domain experts without deep AI knowledge
For example, a mathematical verifier might check whether an equation is correctly solved, while a coding verifier might test whether generated code produces expected outputs.
Democratizing AI Through User-Designed Verifiers
The true significance of inference-time scaling with verifiers lies not in their technical details, but in the paradigm shift they enable.
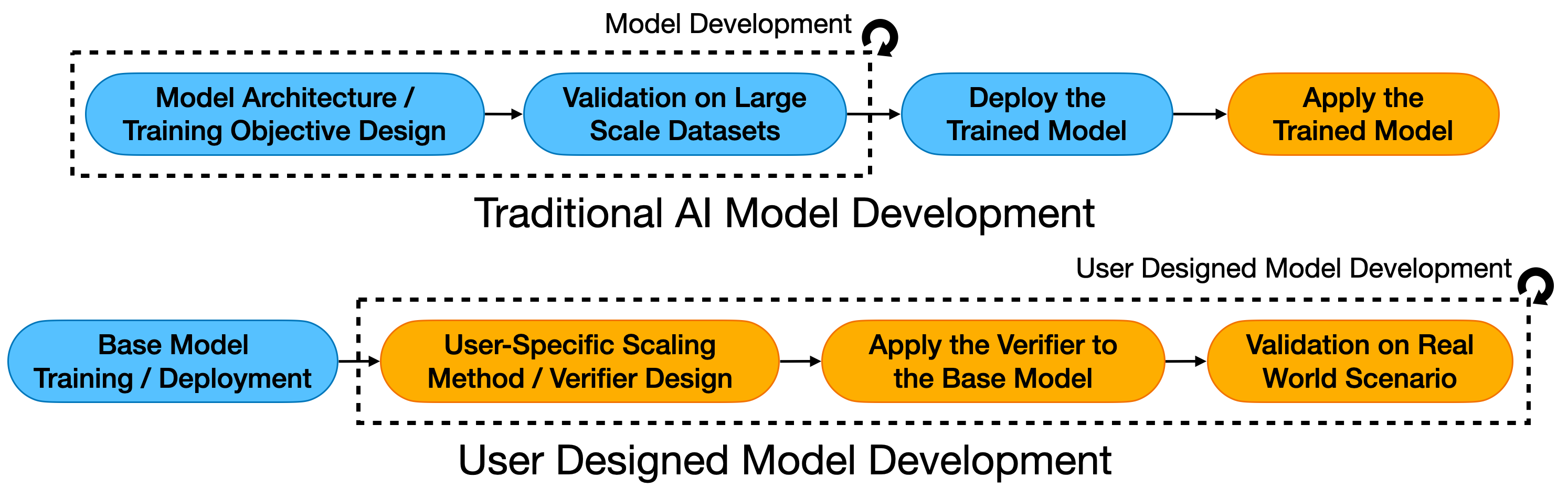
Shifting Design Authority
Traditional AI model deployment concentrates design authority with model creators and AI researchers. They must anticipate all possible use cases and design specialized models for each scenario. This approach faces two key limitations: the impossibility of predicting all use cases, and researchers’ limited domain expertise across diverse fields.
In contrast, inference-time scaling with verifiers clearly separates task-specific knowledge modeling from general model design. This separation allows:
- Model creators to focus on building flexible, general-purpose systems
- Domain experts to design specific verifiers for their use cases
- Users to adapt AI systems without requiring deep knowledge of model architecture
The verifier design requires only domain-specific knowledge to evaluate solution validity, not detailed understanding of artificial intelligence systems. This shift empowers users who know what they want to achieve but lack AI expertise.
Unbounded Extensibility for Reasoning
Since verifier design requires only domain knowledge rather than AI expertise, it opens reasoning capabilities to unprecedented extensibility. Verifiers can be:
- Rule-based systems implementing domain logic
- Simple programs that check solution properties
- Lightweight models trained on small, task-specific datasets
This accessibility contrasts sharply with approaches like RLVR, which require substantial computational resources and extensive training data for each new domain.
Limitations and Challenges
Despite its promise, inference-time scaling faces several challenges:
Computational overhead: When target distributions differ drastically from prior distributions, exploration during inference becomes computationally expensive. The sampling process may require extensive search to find valid solutions.
Verifier quality: The effectiveness of the entire system depends critically on verifier design. Poor verifiers can mislead the generation process or fail to recognize valid solutions.
Exploration efficiency: The quality of exploration strategies becomes critical. Inefficient search algorithms can lead to prohibitive computational costs without guaranteeing solution discovery.
Domain complexity: In complex domains, designing effective verifiers may itself require significant expertise and may not be as straightforward as the democratic vision suggests.
Future Directions
These limitations suggest several promising research directions:
Hybrid approaches: Combining mild fine-tuning with inference-time scaling might offer optimal results—shifting the prior closer to target distributions while maintaining flexibility.
Efficient search: Improving exploration algorithms to reduce computational overhead while maintaining solution quality.
Conclusion
Inference-time scaling with verifiers represents more than a technical advancement—it fundamentally reimagines how AI systems adapt to human needs. By viewing reasoning as navigation from general to sparse distributions and empowering users to guide this navigation through custom verifiers, we unlock a new paradigm of AI accessibility.
However, realizing this vision requires addressing significant technical challenges around computational efficiency, verifier design, and system scalability. The most promising path forward likely involves thoughtful integration of multiple approaches rather than wholesale adoption of any single technique.
As this field evolves, the key will be maintaining the democratic promise of user-guided adaptation while ensuring the resulting systems remain practical, reliable, and beneficial across diverse applications.
References
[1] Jason Wei, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems, 2022.
[2] Guo, Daya, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025).
[3] Yoon, Jaesik, et al. Monte Carlo Tree Diffusion for System 2 Planning. In International Conference on Machine Learning, 2025.
[4] Lee, Gyubin, et al. Adaptive Cyclic Diffusion for Inference Scaling. arXiv preprint arXiv:2505.14036 (2025).